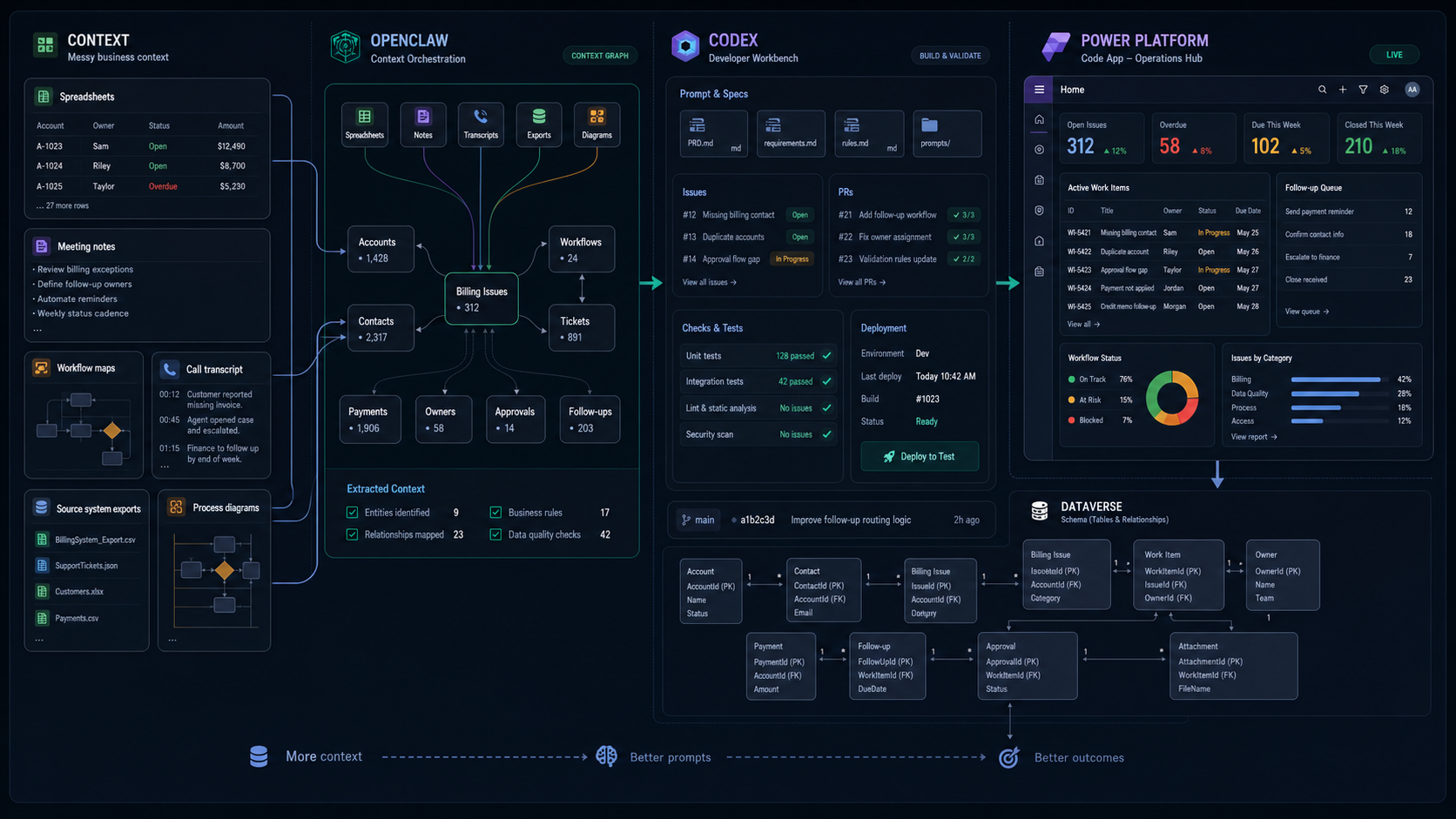
Digital Meld recently built and deployed a Power Apps Code App for a client using OpenClaw, Codex, GitHub issues, Power Platform, and Dataverse. The app pulled together work across operations, finance, supply chain and logistics, marketing, health and safety, field teams, project management, technical delivery, and leadership.
The important part was not a fast first screen. It was keeping the client's business context intact while turning that context into a working system with reviewable decisions, traceable issues, verified pull requests, and clear platform boundaries.
The business problem
Most internal business processes do not live in one clean system. They live across spreadsheets, databases, meeting notes, Teams and SharePoint files, finance tools, field workflows, and a few people who know how the exceptions work because they have lived with the process for years.
The client needed one internal operating surface. Not a marketing site. Not another page of links. A Power Apps Code App where teams could see status, move work forward, find approved resources, and keep cross-functional work from falling through the cracks.
That is where agentic AI becomes useful for businesses: not as a shortcut around process design, but as a way to preserve more context, apply it consistently, and move faster without dropping the controls that real operations require.
OpenClaw carried the context
OpenClaw served as the context layer. It held the working material that usually disappears before implementation starts: spreadsheets, workflow notes, meeting and call transcripts, project history, source-system notes, rough process maps, and the small decisions that shape how the business actually runs.
That context was used to shape the first Dataverse schema JSON, the Mermaid entity relationship diagram, and the business-area workflow map. This mattered because the hard part of a business app is rarely the screen. The hard part is deciding what the work is, where the data should live, who owns it, who can see it, and what done means when multiple departments touch the same process.
OpenClaw kept the messy operating context close enough to use. That made the next layer more useful.
Codex turned context into delivery
Codex became the delivery layer. The first useful output was not code. It was a design-standards file based on a reference interface and the client's design-language material. The goal was not to copy another product. The goal was to translate the useful parts into rules for density, navigation, app shell behavior, typography, color, tables, cards, light and dark mode, and responsive behavior.
Digital Meld also wired Codex into the platform-specific context that Power Apps Code Apps require: Power Platform and Dataverse MCPs, CLIs, generated connector models and services, host behavior, environment targets, authentication assumptions, and deployment rules.
That constraint work matters. An agent that only understands a local React app can produce something that looks fine in preview and fails when the real platform contract shows up.
The planning pass came before implementation
The highest-leverage step was the planning pass. Codex read the repository, reference exports, schema JSON, Mermaid ERD, design standard, and Microsoft Learn documentation for Power Apps Code Apps before implementation began.
The result was a project requirements document that could actually drive delivery. It covered product scope, source-of-truth rules, folder layout, routes, app shell behavior, business-unit navigation, Dataverse ownership, access control, audit and revision history, archive behavior, delivery sequencing, v1 boundaries, roadmap boundaries, and verification gates.
The PRD was then challenged before build work started. The review focused on uncomfortable questions: whether the team was rebuilding from references or migrating old source, which artifact was the source of truth, how schema drift would be handled, which routes belonged in v1, where Dataverse security enforced access, what required explicit platform approval, and which items were real requirements versus roadmap ideas.
Prompts belong in files
One of the most useful habits in the workflow was saving prompts as Markdown files in the repository. That made the prompts reviewable, reusable, and transferable to another developer or agent without depending on a private chat thread.
For the planning pass, the prompt looked like this:
Using all context available in the working directory, create the /plan prompt for this app and save it as a Markdown file.For issue generation, the prompt became:
Analyze the PRD and create a /goal prompt that generates the required GitHub issues with full context for delivering the app. Save the prompt to a Markdown file.For implementation, the prompt pushed Codex into a repeatable delivery loop:
Pull the current repository and GitHub tracker state. Pick the next unblocked issue. Create a branch. Build the smallest useful pull request. Run the named checks. Open the pull request. Fix failures. Merge when ready. Sync main. Continue.The guardrails were written down too:
No production writes without approval. No Dataverse mutation without target confirmation. No role, team, or group mapping changes without approval. No secrets or private business data in fixtures, screenshots, logs, docs, issues, or pull request text. No broad abstractions for imaginary future needs.The PRD became the backlog
Once the PRD was solid, Codex generated GitHub issues from it. Each issue carried the context needed to build that slice: workflow intent, relevant routes, likely files, Dataverse tables, dependencies, acceptance criteria, non-goals, verification steps, and notes about what not to touch.
That changed the handoff unit. The issue, not the chat thread, became the durable work package. A developer or another agent could take a single issue and understand the work without replaying the entire planning session.
Implementation then moved through pull-request-sized slices: shared shell, route foundation, business-unit switching, desktop sidebar, mobile navigation, search, alerts, help, theme switching, offline indication, access-filtered navigation, Dataverse schema metadata, generated Code Apps models and services, and a schema validator to keep the PRD, JSON schema, and Mermaid ERD aligned.
The final Dataverse contract reached 89 tables, 1,148 columns, and 156 relationships. That scale is exactly why source-of-truth rules, generated artifacts, validation, and issue-level context had to be part of the workflow from the start.
Verification stayed in the loop
The check matched the work. Schema changes used the schema validator. App changes used lint and build checks. UI and route behavior used Playwright. Visual work used screenshots. Power Platform work used deployment notes and explicit environment gates.
One access-validation item stayed open because it needed representative-user validation in the production environment. That was tracked instead of waved away. For client systems, unresolved operational validation belongs in the tracker where owners can see it.
What this says about agentic AI
The model was not the strategy. The process was the strategy.
OpenClaw carried long-running business context. Codex turned that context into files, issues, pull requests, checks, and deployment notes. GitHub preserved the decision trail. Power Platform and Dataverse enforced the platform contract.
That is how Digital Meld approaches agentic AI for businesses: define the operating model first, protect data and credential boundaries, keep approval gates visible, give agents scoped authority, verify the work, and leave a paper trail that another person can trust later.
The result is not magic. It is better leverage, better context retention, and fewer dropped details while building real software for real operations.